Why AI Training Data Matters for Your Brand
When someone asks ChatGPT for a hotel recommendation or asks Claude to compare running shoes, the AI model pulls from two sources: knowledge it learned during training, and information it finds by searching the web in real time. The training data is the foundation. It shapes how AI understands your brand, your category, and your competitors before a single search ever happens.
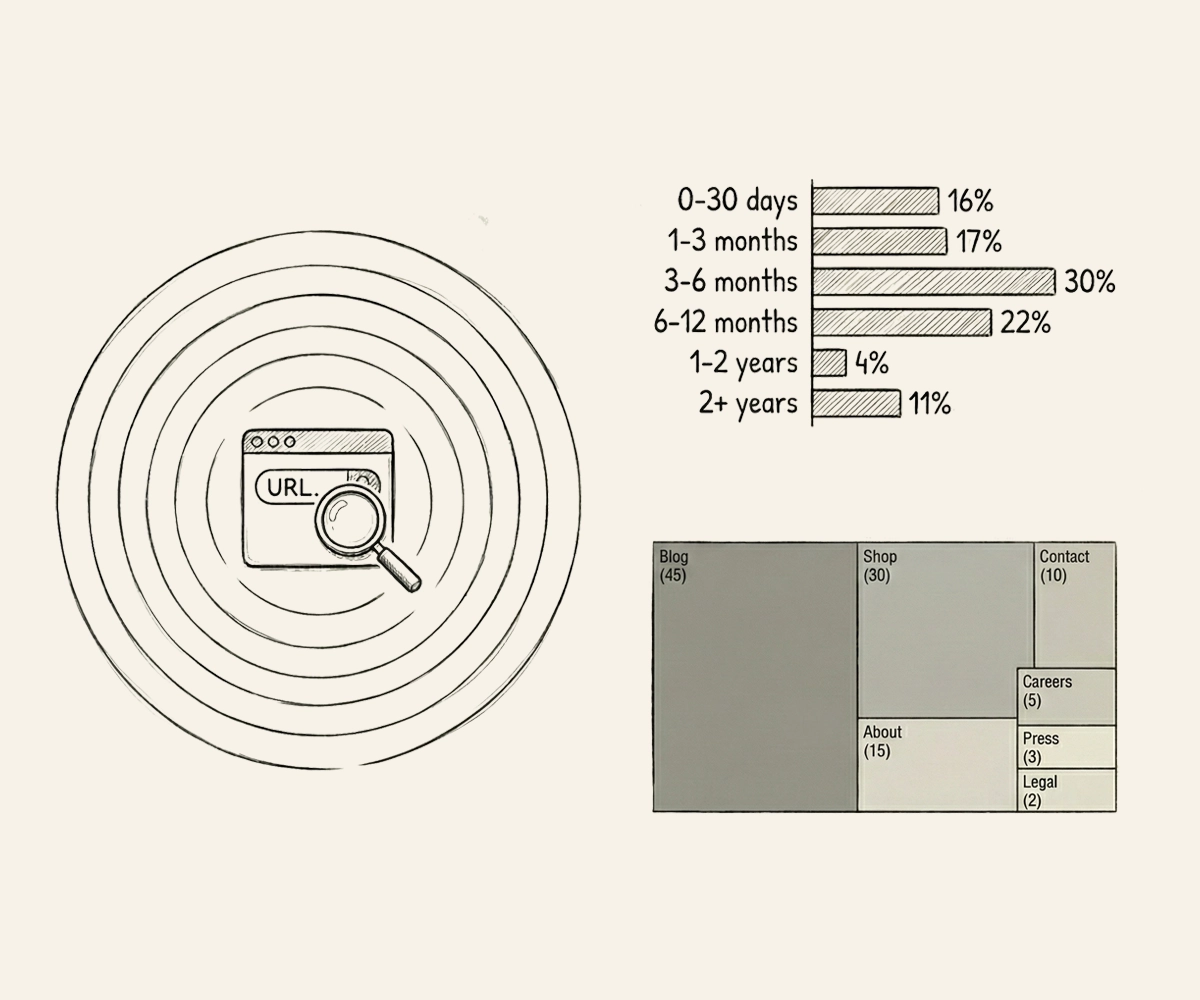
Most large language models are trained on Common Crawl, an open dataset containing over 300 billion web pages spanning 19 years. With 3 to 5 billion new pages added each month, Common Crawl is the closest thing to a shared knowledge base for AI. If your website is well-represented in it, AI models have direct access to your content, your messaging, and your product information. If you’re missing or underrepresented, AI fills in the gaps with whatever third-party sources it can find: review sites, forums, competitor pages, and aggregators you don’t control.
Training Data vs. Live Search
There’s a critical distinction between what AI knows from training and what it can find in real time. Training data is like a closed-book exam. The model answers based on what it has already absorbed, and that information can be months or even years old. Live search is the open-book version, where models like Perplexity and ChatGPT with browsing pull fresh results from the web. Both matter, but training data is the default. Most AI responses draw on it first, and only reach for live search when the model recognizes it needs more current information.
What Happens When Your Coverage Is Limited
If your competitors have hundreds of pages indexed and you have a handful, the math is simple. AI has more information about them, more confidence in recommending them, and more context to draw from when answering questions about your category. Limited coverage doesn’t mean you’re invisible, but it means you’re competing with one hand tied behind your back. The AI Training Data Checker gives you a baseline. Centium subscribers get the full picture: knowledge cutoff analysis showing what’s baked into each model’s brain, crawl history tracking over time, and the most recently indexed pages on your site.